
What 2,200+ buyer discussions reveal about open-source LLM adoption in 2026 (Mistral, Hugging Face, DeepSeek, Cohere)
While open-source LLMs are high on enterprise shortlists, conversion is mixed.
This report breaks down the data from Qualitate 1H ’26 Data Management & AI study, featuring 2,200+ structured discussions with senior technology buyers, benchmarked against prior studies.
Download the full report to compare how four open-source vendors are being evaluated, adopted, and rejected: Mistral AI, Hugging Face, DeepSeek, and Cohere.
What did the study find on open-source LLM adoption?
Evaluation is up. Buyers are evaluating open-source vendors heavily (Mistral AI is tied for #2 most-evaluated in LLMs), but the gap between who gets evaluated and who gets deployed is uneven.
Cost and sovereignty attract enterprise buyers. Mistral and Hugging Face are gaining spend on cost efficiency, EU data sovereignty, and the ability to fine-tune and self-host open weights on sensitive data.
Trust and model quality decide where workloads go. DeepSeek draws strong evaluation interest on price, but is losing on security and data-privacy concerns tied to Chinese ownership. Frontier labs still win the high-value reasoning work.
Note: 73% of our Data Management & AI panel consists of respondents in North America.
Why is Mistral AI gaining?
Mistral posts some of the strongest current account spend growth in the study, now in the 87th percentile, and ties for the #2 most-evaluated LLM. EU data sovereignty and cost efficiency are among the drivers.
“The main reason for moving forward with Mistral was primarily because of the organization’s EU headquarters, and their appetite for the risk within the US market, given the ups and downs that have been within the news lately with Claude and Grok. So we opted to move forward with a local to the EU region rather than a US-based vendor.”
– IT PM, Manufacturing & Logistics, Large Enterprise
What’s driving Hugging Face’s spend and evaluations?
Hugging Face runs an open-core freemium model, and its spend growth sits in the 81st percentile. Buyers increase spend to fine-tune open-source models on their own data and as compute consumption rises in production. Its evaluation rate runs above the industry average.
“The nice thing about it is that you can download the model weights and fine tune them yourself… for our most sensitive internal data, we can run models on Hugging Face without having to send out our data through an API call, which is nice.”
– Head of Data Science, Non-Profit & Education
Why does DeepSeek struggle to convert its top-of-funnel?
DeepSeek attracts strong evaluation interest on its cost structure, then converts well below the 73% industry average. It shows 100% feature misalignment on regulatory, compliance, and security capabilities. The reason buyers gave is consistent: Chinese ownership and data-privacy concerns.
“DeepSeek, I have serious security concerns that we’ve blocked it out of our environment. Period. End of story.”
– Chief Information Officer, Government, Non-Profit & Education
“We also actually looked at DeepSeek AI. It had the low cost from an API usage perspective, but the model is very poor, so that’s why we’re not going with it.”
– Head of Product Digital Business Banking, Financial Services & Insurance
Where does Cohere win?
Cohere’s spend increases and evaluations are both driven by RAG and search-pipeline performance. The limited negativity it sees comes almost entirely from failed evaluations, not from buyers churning off the product.
What’s in the full report?
- Current account spend growth for Mistral AI and Hugging Face, with the buyer reasoning behind them
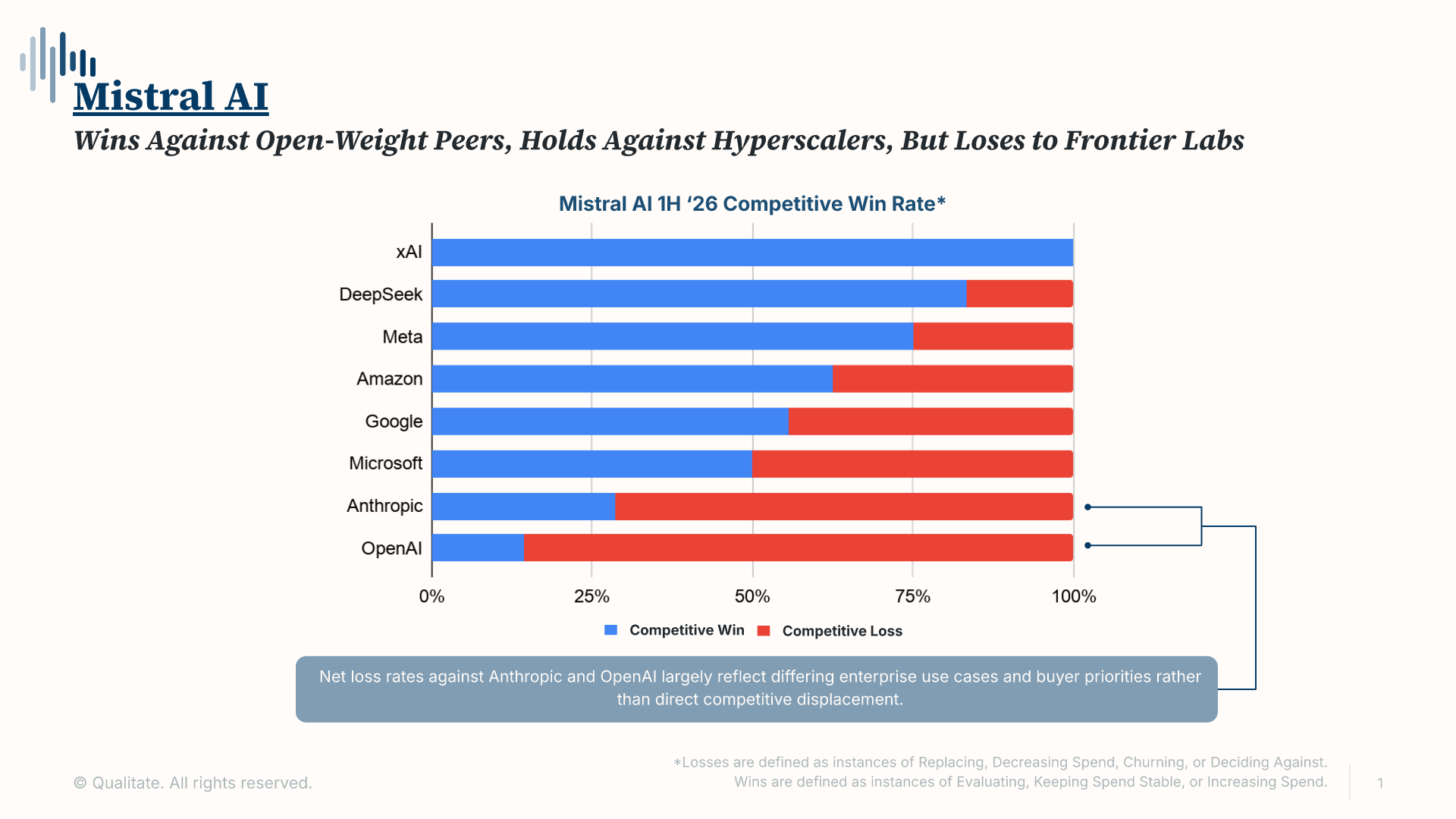
- Mistral’s top-of-funnel position and its win/loss profile against open-weight peers, hyperscalers, and frontier labs
- Hugging Face evaluation drivers: open-model catalog, fine-tuning, and locally-hosted models
- DeepSeek’s evaluation-to-conversion gap and the security, privacy, and model-quality reasons behind it
- Cohere’s RAG and search strength, plus the reasons buyers pass or hold spend flat
- Verbatim buyer quotes behind every metric, and key definitions (NTM spend growth, evaluation rate, conversion rate, feature alignment)
Subscribe to the Qualitate newsletter
.jpg)
.png)